



Big Data Cogn. Comput. 2024, 8(6), 57; https://doi.org/10.3390/bdcc8060057 - 31 May 2024
Abstract
►
Show Figures
Cardiovascular diseases (CVDs) are highly prevalent, sudden onset, and relatively fatal, posing a significant public health burden. Long-term dynamic electrocardiography, which can continuously record the long-term dynamic ECG activities of individuals in their daily lives, has high research value. However, ECG signals are
[...] Read more.
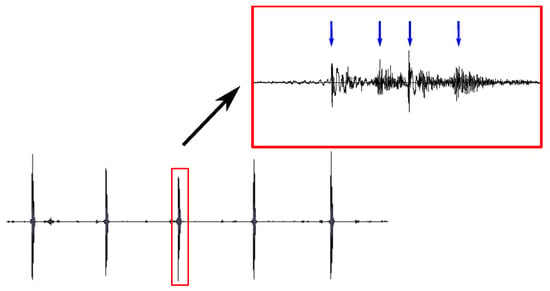
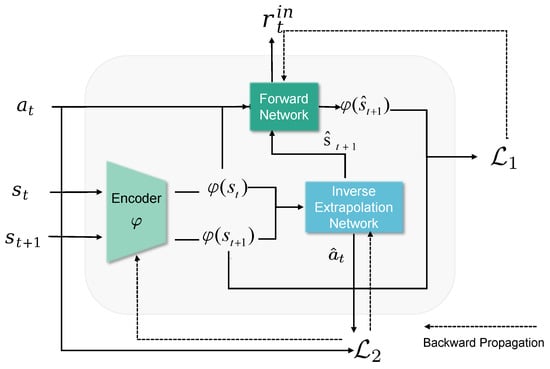
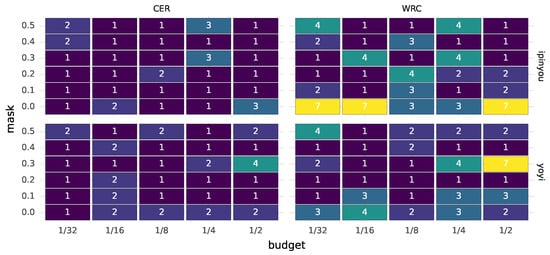
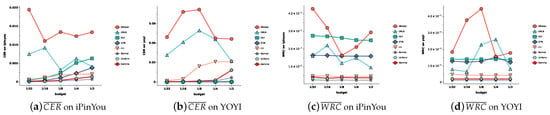
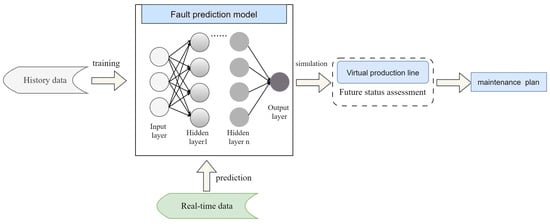
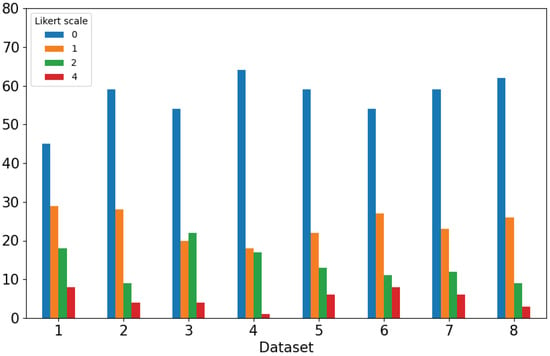
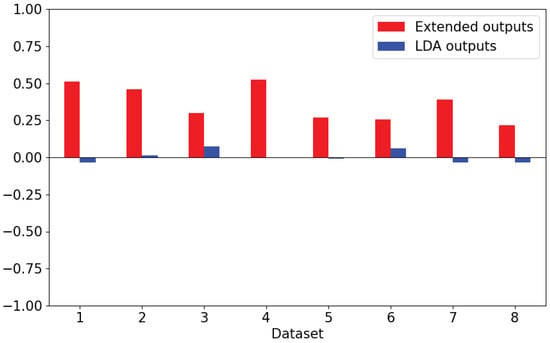
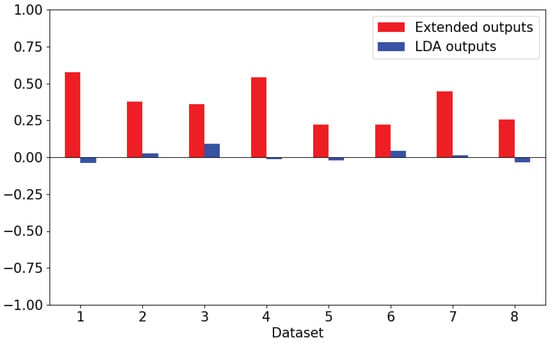
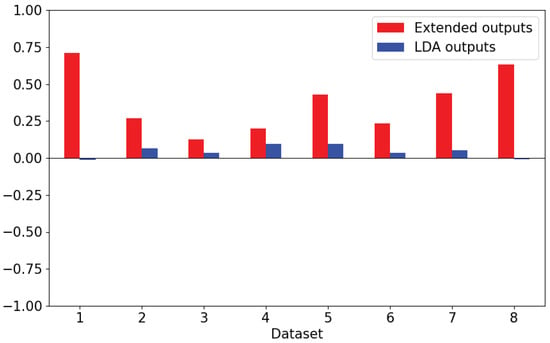
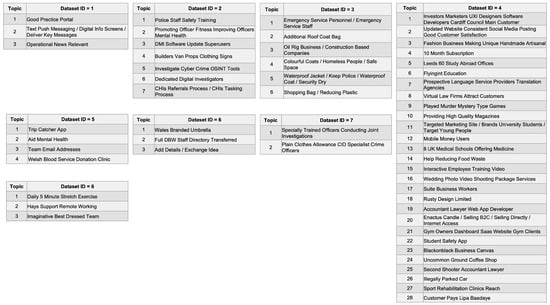
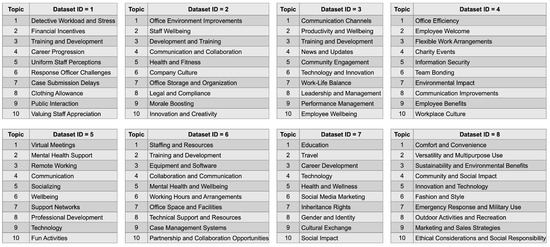
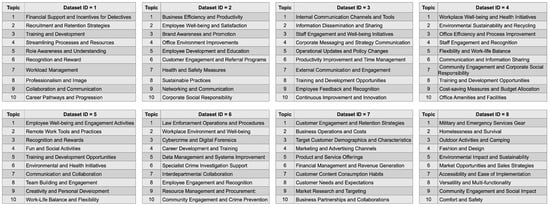
Cardiovascular diseases (CVDs) are highly prevalent, sudden onset, and relatively fatal, posing a significant public health burden. Long-term dynamic electrocardiography, which can continuously record the long-term dynamic ECG activities of individuals in their daily lives, has high research value. However, ECG signals are weak and highly susceptible to external interference, which may lead to false alarms and misdiagnosis, affecting the diagnostic efficiency and the utilization rate of healthcare resources, so research on the quality of dynamic ECG signals is extremely necessary. Aimed at the above problems, this paper proposes a dynamic ECG signal quality assessment method based on CNN and LSTM that divides the signal into three quality categories: the signal of the Q1 category has a lower noise level, which can be used for reliable diagnosis of arrhythmia, etc.; the signal of the Q2 category has a higher noise level, but it still contains information that can be used for heart rate calculation, HRV analysis, etc.; and the signal of the Q3 category has a higher noise level that can interfere with the diagnosis of cardiovascular disease and should be discarded or labeled. In this paper, we use the widely recognized MIT-BIH database, based on which the model is applied to realistically collect exercise experimental data to assess the performance of the model in dealing with real-world situations. The model achieves an accuracy of 98.65% on the test set, a macro-averaged F1 score of 98.5%, and a high F1 score of 99.71% for the prediction of Q3 category signals, which shows that the model has good accuracy and generalization performance.
Full article

Figure 1













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
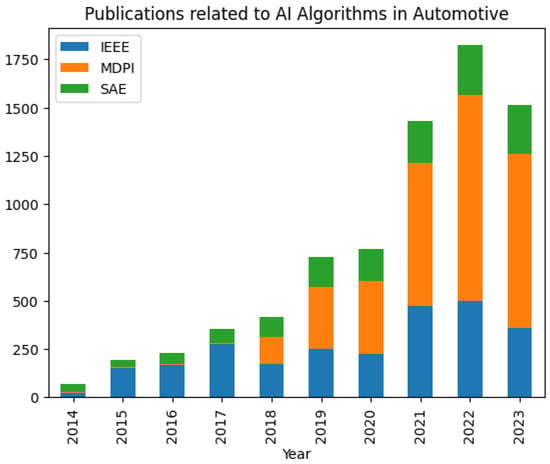{kind=link}
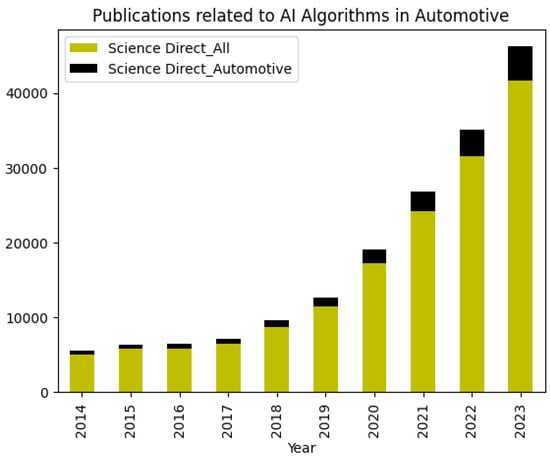{kind=link}
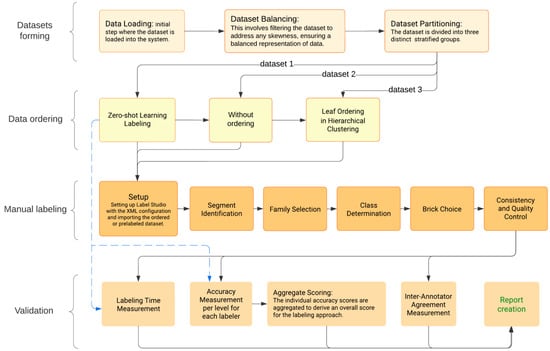{kind=link}
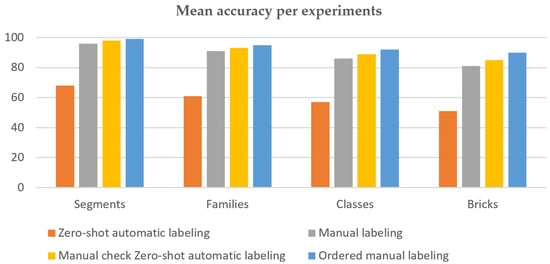{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
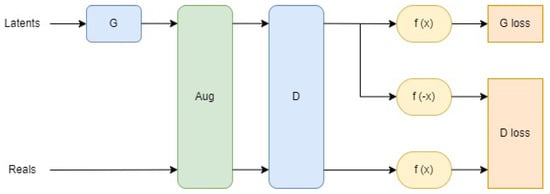{kind=link}
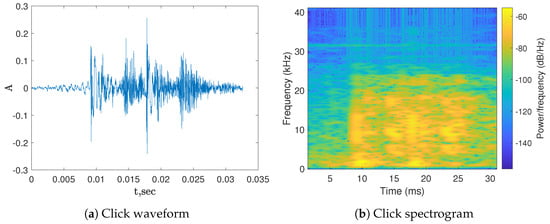{kind=link}
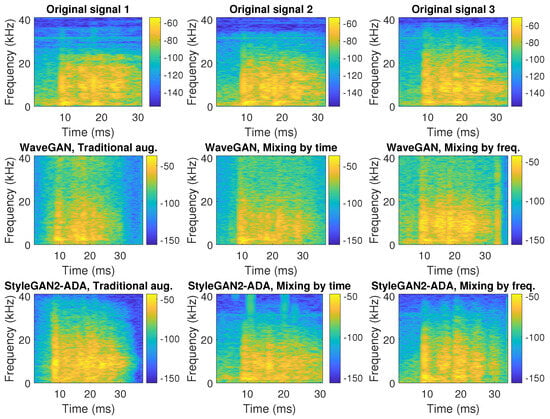{kind=link}
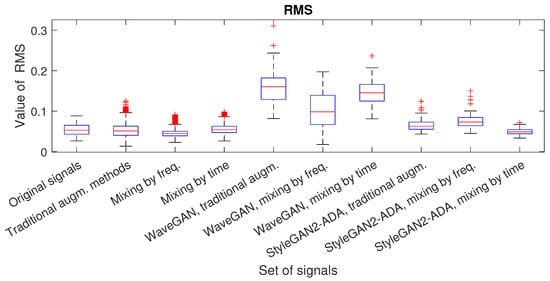{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}